Kinesis Consumer

The Kinesis Consumer step gets and processes data records from Amazon Kinesis Data Streams (KDS). This step is useful for managing your Amazon KDS Applications. When you set up an Amazon KDS application in the Kinesis Consumer step, the name property uniquely identifies the application that is associated with your AWS account and geographical region of the data stream. Then your consumer is ready to get and process data records from the indicated Kinesis data stream.
In the PDI Kinesis Consumer step itself, you can define the location for processing, as well as the specific data formats to stream data and system metrics. You can set up this step to collect monitored events, track user consumption of data streams, and monitor alerts.
The Kinesis Consumer step pulls streaming data from Amazon Kinesis Data Streams (KDS) through a PDI transformation. The parent Kinesis Consumer step runs a child transformation that executes according to message batch size or duration, so you can process a continuous stream of records in near real-time. The child transformation must start with the Get records from stream step.
You can configure the Kinesis Consumer step to continuously ingest streaming data from the Kinesis Data Streams. Depending on your setup, you can execute the transformation within PDI or within the Adaptive Execution Layer (AEL), using Spark as the processing engine. When using Spark, you must execute the child transformation according to Duration (ms) only.
Additionally, in the Kinesis Consumer step, you can select a step in the child transformation to stream records back to the parent transformation. Records processed by a Kinesis Consumer step in a parent transformation can then be passed downstream to any other steps included within the same parent transformation.
AEL considerations
When using the Kinesis Consumer step with the Adaptive Execution Layer, the following may affect performance and results.
- When running the Kinesis Consumer step on AEL Spark, use HDP 3.x. Earlier versions of HDP are not supported.
General
The Kinesis Consumer step requires definitions for setup, batch, result fields, and Kinesis Data Streams specific options to consume messages.
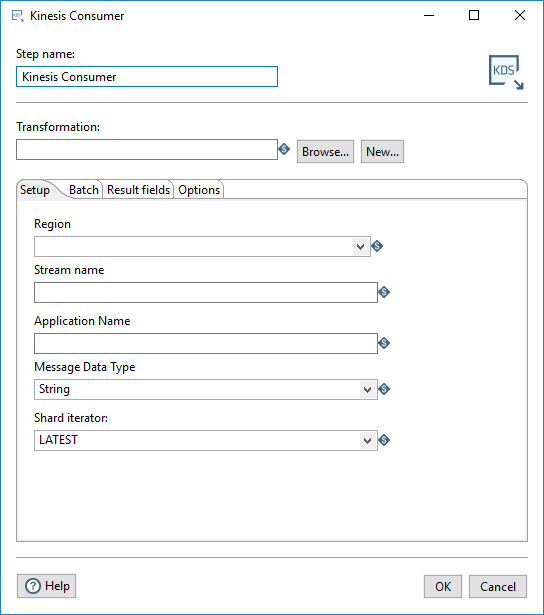
Enter the following information in the Step name and Transformation fields:
| Option | Description |
| Step name | Specifies the unique name of the step on the canvas. The Step name is set to Kinesis Consumer by default. |
| Transformation | Specify the child transformation to execute by performing any of
the following actions.
The selected child transformation must start with the Get Records from Stream step. If you select a transformation that has the same root path as the current transformation, the variable ${Internal.Entry.Current.Directory} is automatically inserted in place of the common root path. For example, if the current transformation's path is /home/admin/transformation.ktr and you select a transformation in the directory /home/admin/path/sub.ktr, then the path is automatically converted to ${Internal.Entry.Current.Directory}/path/sub.ktr. If you are working with a repository, you must specify the name of the transformation. If you are not working with a repository, you must specify the XML file name of the transformation. Transformations previously specified by reference are automatically converted to be specified by the transformation name in the Pentaho Repository. |
Create and save a new child transformation
Procedure
In the Kinesis Consumer step, click New.
The Save As dialog box appears.Navigate to the location where you want to save your new child transformation, then type in the file name.
Click Save.
A notification box displays informing you that the child transformation has been created and opened in a new tab. If you do not want to see this notification in the future, select the Don't show me this again check box.Click the new transformation tab to view and edit the child transformation.
It automatically contains the Get Records from Stream step. Optionally, you can continue to build this transformation and save it.When finished, return to the Kinesis Consumer step.
Options
The Kinesis Consumer step features several tabs. Each tab is described below.
Setup tab
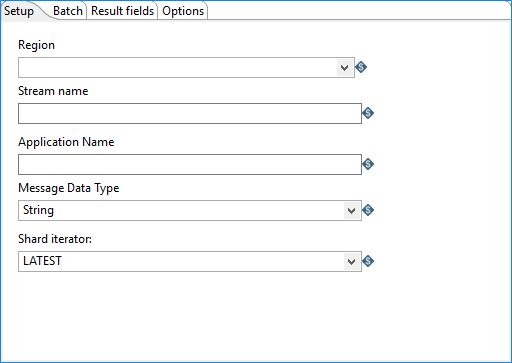
In this tab, define your specific data stream within Amazon Kinesis Data Streams and the related starting location for consuming records. The records in the Amazon Kinesis Data Streams are stored by the data stream name and geographical areas known as regions. A Kinesis Data Streams application reads the records from the data stream. The name property of the Kinesis application specifies a consumer of the data stream and uniquely identifies the last point at which this consumer has read from the data stream.
Groups of records in Amazon Kinesis Data Streams are known as shards. The shard iterator property narrows the location of the records in a shard if a given application name has never been used to read from a data stream before. See https://docs.aws.amazon.com/streams/latest/dev/key-concepts.html and https://docs.aws.amazon.com/streams/latest/dev/kinesis-record-processor-implementation-app-java.html for more information on Amazon Kinesis Data Streams applications and shards.
| Option | Description |
| Region | Specify the Amazon geographical area where the data stream occurs. You can only select one region. |
| Stream name | Specify the name of the specific data stream within Amazon Kinesis Data Streams that contains the records to be consumed. |
| Application Name | Specify the name property of the existing Amazon Kinesis Data Streams application used to get records from a data stream. A given Application Name must not be used with more than one Stream name. Do not consume records from more than one data stream at a time. |
| Message Data Type | Select the data type of records to be retrieved. You can consume either String or Binary data stream. The default value is String. |
| Shard iterator | If you are using an application (as specified in
Application Name) for the first time to locate records to
consume, select how to further refine the starting location for consuming data. The
following iterator options are available:
|
Batch tab
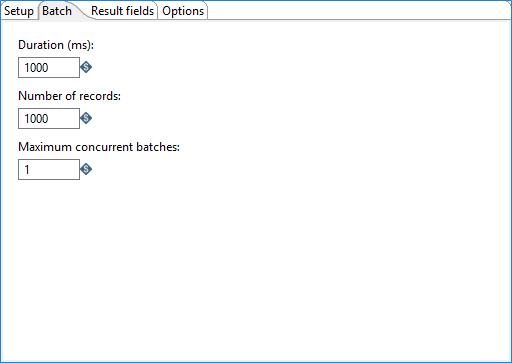
Use this tab to designate how many messages to consume before processing. You can specify message count and/or a specific amount of time.
How many messages consumed before processing is defined by either the Duration (ms) or the Number of records option. Messages are consumed when either the specified duration or number of records occur. For example, if Duration (ms) is set to 1000 milliseconds and Number of records is 1000, messages are consumed for processing whenever time intervals of 1000 milliseconds are reached or 1000 records have been received. If you set either option to zero, PDI will ignore that parameter.
You can also specify the maximum number of batches used to collect records at the same time.
| Option | Description |
| Duration (ms) | Specify a time in milliseconds. This value is the amount of time
the step will spend collecting records prior to the execution of the
transformation. If this option set to a value of 0, then Number of records triggers consumption. Either the Duration or the Number of records option must contain a value greater than 0 to run the transformation. Note: You must set this field if you are using Spark as your processing engine. |
| Number of records | Specify a number. After every ‘X’ number of records, the specified
transformation will be executed and these ‘X’ records will be passed to the
transformation. If this option set to a value of 0 then Duration triggers consumption. Either the Duration or the Number of records option must contain a value greater than 0 to run the transformation. |
| Maximum concurrent batches | Specify the maximum number of batches used to collect records at
the same time. The default value is 1, which
indicates a single batch is used for collecting records. This option should only be used when your consumer step cannot keep pace with the speed at which the data is streaming. Your computing environment must have adequate CPU and memory for this implementation. An error will occur if your environment cannot handle the maximum number of concurrent batches specified. |
Result fields tab
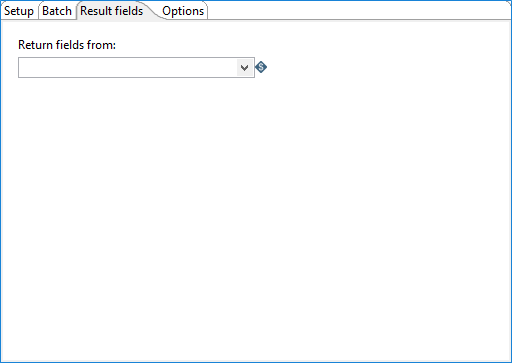
Use this tab to select the step from the child transformation that will stream records back to the parent transformation. Records processed by a Kinesis Consumer step in the parent transformation can then be passed downstream to any other steps included within the same parent transformation.
Return fields from
Select the name of the step from the child transformation to stream fields back to the parent transformation. The data values in these returned fields are available to any subsequent downstream steps in the parent transformation.
Options tab
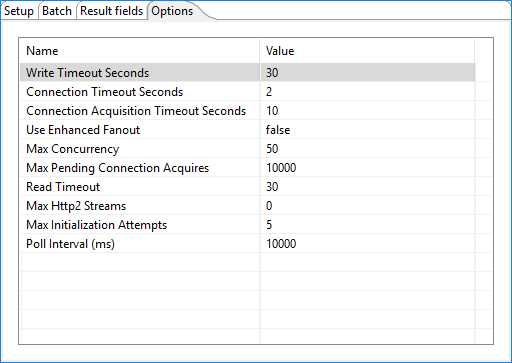
Use this tab to configure additional properties for ingesting records from a data stream within Amazon Kinesis Data Streams. You should have advance understanding of Amazon Kinesis Data Streams before considering how to best adjust these properties from their default values. See https://docs.aws.amazon.com/streams/latest/dev/kinesis-record-processor-implementation-app-java.html for more details.
| Property | Description |
| Write Timeout Seconds | Amount of time to wait for PDI to acknowledge back to Amazon Kinesis Data Streams that the last point in a data stream has been reached before an exception is thrown. |
| Connection Timeout Seconds | Amount of time to wait when initially establishing a connection before giving up and timing out. |
| Connection Acquisition Timeout | Amount of time to wait when acquiring a connection from the pool before giving up and timing out. |
| Use Enhanced Fanout | If true, consumers receive records from a
stream with throughput of up to 2 MiB of data per second per shard. The default is
false. Setting Use Enhanced Fanout to true incurs additional costs with Amazon Web Services (AWS). See https://docs.aws.amazon.com/streams/latest/dev/introduction-to-enhanced-consumers.html and https://aws.amazon.com/kinesis/data-streams/pricing/ for further details. |
| Max Concurrency | Maximum number of allowed concurrent requests. |
| Max Pending Connection Acquires | Maximum number of requests allowed to queue up once Max Concurrency is reached . |
| Read Timeout | Amount of time to wait for a read on a socket before an exception is thrown. |
| Max Http2 Streams | Maximum number of concurrent streams for an HTTP/2 connection. |
| Max Initialization Attempts | Maximum number of attempts to initialize. |
| Poll Interval (ms) | Interval in milliseconds between attempts to initialize. |
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.