Logging and performance monitoring

Pentaho Data Integration provides you with several methods in which to monitor the performance of jobs and transformations. Logging offers you summarized information regarding a job or transformation such as the number of records inserted and the total elapsed time spent in a transformation. In addition, logging provides detailed information about exceptions, errors, and debugging details.
You may want to enable logging and step performance monitoring to determine if a job completed with errors or to review errors that were encountered during processing. In headless environments, most ETL in production is not run from the graphical user interface and you need a place to watch initiated job results. Performance monitoring can provide you with useful information for both current performance problems and capacity planning.
To see what effect your transformation will have on the data sources it includes, go to the Action menu and click on Impact. PDI will perform an impact analysis to determine how your data sources will be affected by the transformation if it is completed successfully.
If you are an administrative user and want to monitor jobs and transformations, you must first set up logging and performance monitoring in Spoon. For more information about monitoring jobs and transformations, see the Monitoring System Performance section.
Set up logging
Procedure
Have your system administrator create a database or table space called pdi_logging.
Right-click in the workspace (canvas) where you have an open transformation and select Properties, or press CTRLT.
The Transformation Properties dialog box appears.In the Transformation Properties dialog box, click the Logging tab. Select which type of logging you want to use in the navigation pane on the left.
Under Logging, enter the following information:
Option Description Log Connection Specifies the database connection you are using for logging. You can configure a new connection by clicking New.
Log table schema Specifies the schema name, if supported by your database. Log table name Specifies the name of the log table.
Logging interval (seconds) Specifies the interval in which logs are written to the table.
This property only applies to Transformation and Performance logging types.
Log record timeout (in days) Specifies the number of days to keep log entries in the table before they are deleted.
Log size limit in lines Limits the number of lines that are stored in the LOG_FIELD. PDI stores logging for the transformation in a long text field (CLOB).
This property only applies to the Transformation logging type.
Select the fields you want to log in the Fields to log pane, or keep the default selections.
Click SQL to open the Simple SQL Editor.
Enter your SQL statements in the Simple SQL Editor.
Click Execute to execute the SQL code to create your log table, then click OK to exit the Results dialog box.
Click Close to exit the Simple SQL Editor.
Click OK to exit the Transformation Properties dialog box.
Results
Logging levels
When you run a job or transformation that has logging enabled, you have the following log level verbosity options in the Run Options window:
| Log Level | Description |
| Nothing | Do not record any logging output. |
| Error | Only show errors. |
| Minimal | Only use minimal logging. |
| Basic | This is the default level. |
| Detailed | Give detailed logging output. |
| Debug | For debugging purposes, very detailed output. |
| Row Level | Logging at a row level. This will generate a lot of log data. |
If the Enable time option is selected, all lines in the logging will be preceded by the time of day.
Monitor performance
There are a few ways that you can monitor step performance in PDI. Two tools are particularly helpful: the Sniff Test tool and the Monitoring tab. You can also use graphs to view performance.
Sniff Test tool
To use this, complete these steps:
Procedure
Right-click a step in the transformation as it runs.
Select Sniff Test During Execution.
There are three options in this menu:- Sniff test input rows - Shows the data inputted into the step.
- Sniff test output rows - Shows the data outputted from the step.
- Sniff test error handling - Shows error handling data.
Results
Monitoring tab
You enable the step performance monitoring in the Transformation Properties dialog box:
Procedure
Right-click in the workspace that is displaying your transformation and select Transformation Settings.
You can also access the Transformation Properties dialog box, by pressing CTRLT.In the dialog box, select Enable step performance monitoring?
Results
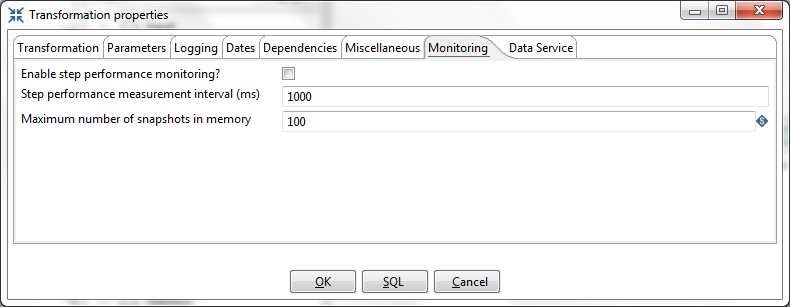
Step performance monitoring may cause memory consumption problems in long-running transformations. By default, a performance snapshot is taken for all the running steps every second. This is not a CPU-intensive operation and, in most instances, does not negatively impact performance unless you have many steps in a transformation or you take a lot of snapshots (several per second, for example). You can control the number of snapshots in memory by changing the Maximum number of snapshots in memory value. In addition, if you run in Spoon locally you may consume a fair amount of CPU power when you update the JFreeChart graphics under the Performance tab. Running in "headless" mode (Kitchen, Pan, Pentaho Server [slave server], Carte, Pentaho BI platform, and so on) does not have this drawback and should provide you with accurate performance statistics.
Use performance graphs
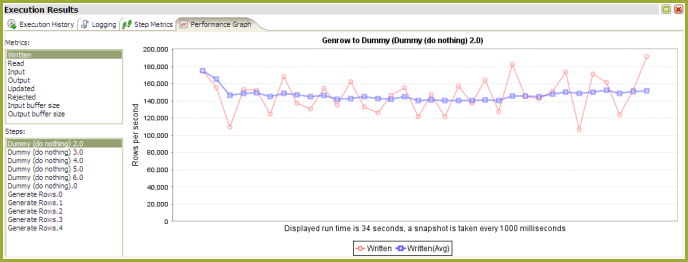
If you configured step performance monitoring with database logging, you can view performance evolution graphs. Performance graphs provide you with a visual interpretation of how your transformation is processing. To view Performance Graphs, make sure you enable the Performance logging type.
PDI performance tuning tips
The tips described here may help you to identify and correct performance-related issues associated with PDI transformations.
| Step | Tip | Description |
| JS | Turn off compatibility mode |
Rewriting JavaScript to use a format that is not compatible with previous versions is, in most instances, easy to do and makes scripts easier to work with and to read. By default, old JavaScript programs run in compatibility mode. That means that the step will process like it did in a previous version. You may see a small performance drop because of the overload associated with forcing compatibility. If you want to make use of the new architecture, disable compatibility mode and change the code as shown below:
Instead of Java methods, use the built-in library. Notice that the resulting program code is more intuitive. For example:
If you convert your code as shown above, you may get significant performance benefits. NoteIt is no longer possible to modify data in-place using the value methods. This
was a design decision to ensure that no data with the wrong type would end up in
the output rows of the step. Instead of modifying fields in-place, create new
fields using the table at the bottom of the Modified JavaScript
transformation.
|
| JS | Combine steps | One large JavaScript step runs faster than three consecutive smaller steps. Combining processes in one larger step helps to reduce overhead. |
| JS | Avoid the JavaScript step or write a custom plug in | Remember that while JavaScript is the fastest scripting language for Java, it is still a scripting language. If you do the same amount of work in a native step or plugin, you avoid the overhead of the JS scripting engine. This has been known to result in significant performance gains. It is also the primary reason why the Calculator step was created — to avoid the use of JavaScript for simple calculations. |
| JS | Create a copy of a field | No JavaScript is required for this, a Select Values step does the trick. You can specify the same field twice. Once without a rename, once (or more) with a rename. Another trick is to use B=NVL(A,A) in a Calculator step where B is forced to be a copy of A. |
| JS | Data conversion | Consider performing conversions between data types (dates, numeric data, and so on) in a Select Values step. You can do this in the Metadata tab of the step. |
| JS | Variable creation | If you have variables that can be declared once at the beginning of the transformation, make sure you put them in a separate script and mark that script as a startup script (right click on the script name in the tab). JavaScript object creation is time consuming so if you can avoid creating a new object for every row you are transforming, this will translate to a performance boost for the step. |
| N/A | Launch several copies of a step | There are two important reasons why launching multiple copies of a step may
result in better performance:
|
| N/A | Manage thread priorities | This feature that is found in the Transformation Settings dialog box under the (Misc tab) improves performance by reducing the locking overhead in certain situations. This feature is enabled by default for new transformations that are created in recent versions, but for older transformations this can be different. |
| Select Values | If possible, don't remove fields in Select Values | Don't remove fields in Select Value unless you must. It's a CPU-intensive task as the engine needs to reconstruct the complete row. It is almost always faster to add fields to a row rather than delete fields from a row. |
| Get Variables | Watch your use of Get Variables | May cause bottlenecks if you use it in a high-volume stream (accepting input). To solve the problem, take the Get Variables step out of the transformation (right click, detach) then insert it in with a Join Rows step. Make sure to specify the main step from which to read in the Join Rows step. Set it to the step that originally provided the Get Variables step with data. |
| N/A | Use new text file input | The CSV File Input or Fixed File Input steps provide optimal performance. If you have a fixed width (field/row) input file, you can even read data in parallel. (multiple copies) These new steps have been rewritten using Non-blocking I/O (NIO) features. Typically, the larger the NIO buffer you specify in the step, the better your read performance will be. |
| N/A | When appropriate, use lazy conversion | In instances in which you are reading data from a text file and you write the data back to a text file, use Lazy conversion to speed up the process. The principle behind lazy conversion that it delays data conversion in hopes that it isn't necessary (reading from a file and writing it back comes to mind). Beyond helping with data conversion, lazy conversion also helps to keep the data in "binary" storage form. This, in turn, helps the internal Kettle engine to perform faster data serialization (sort, clustering, and so on). The Lazy Conversion option is available in the CSV File Input and Fixed File Input text file reading steps. |
| Join Rows | Use Join Rows | You need to specify the main step from which to read. This prevents the step from performing any unnecessary spooling to disk. If you are joining with a set of data that can fit into memory, make sure that the cache size (in rows of data) is large enough. This prevents (slow) spooling to disk. |
| N/A | Review the big picture: database, commit size, row set size and other factors | Consider how the whole environment influences performance. There can be limiting factors in the transformation itself and limiting factors that result from other applications and PDI. Performance depends on your database, your tables, indexes, the JDBC driver, your hardware, speed of the LAN connection to the database, the row size of data and your transformation itself. Test performance using different commit sizes and changing the number of rows in row sets in your transformation settings. Change buffer sizes in your JDBC drivers or database. |
| N/A | Step Performance Monitoring | Step Performance Monitoring is an important tool that allows you identify the slowest step in your transformation. |
Logging best practices
You can improve your logging with log rotation and other best practices.