Merge rows (diff)

The Merge rows (diff) step compares and merges data within two rows of data. This step is useful for comparing data collected at two different times. For example, the source system of your data warehouse might not contain a timestamp of the last data update. You could use this step to compare the two data streams and merge the dates and timestamps in the rows.
Based on keys for comparison, this step merges reference rows (previous data) with compare rows (new data) and creates merged output rows. A flag in the row indicates how the values were compared and merged. Flag values include:
identical
The key was found in both rows, and the compared values are identical.
changed
The key was found in both rows, but one or more compared values are different.
new
The key was not found in the reference rows.
deleted
The key was not found in the compare rows.
If the rows are flagged as deleted, the merged output rows are created based
upon the original reference rows stream.
For identical, new, or changed rows, the
merged output rows are created based upon the original compare rows stream.
You can also send values from the merged and flagged rows to a subsequent step in your transformation, such as the Switch-Case step or the Synchronize after merge step. In the subsequent step, you can use the flag field generated by Merge rows (diff) to control updates/inserts/deletes on a target table.
AEL considerations
When using the Merge rows (diff) step with the Adaptive Execution Layer, the following factors affect performance and results:
- Sorting is not required to produce correct results when using the Spark transformation engine.
- Output from the Merge rows (diff) step is not automatically sorted.
General
Enter the following information for the step:
- Step name: Specify the unique name of the transformation on the canvas. You can customize the name or leave it as the default.
Options
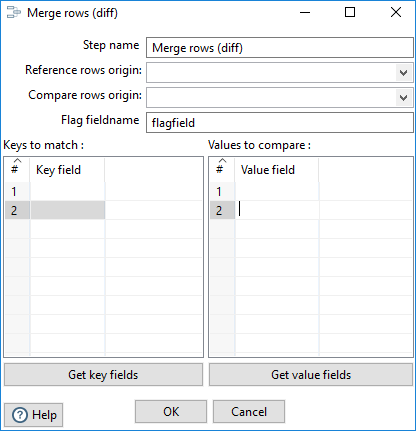
The Merge rows (diff) step contains the following options.
| Option | Description |
| Reference rows origin | From the drop-down list, select the input source for the original reference rows you want to compare. The input source will be a previous step in the transformation. |
| Compare rows origin | From the drop-down list, select the input source for the compare rows. The input source will be a previous step in the transformation. |
| Flag fieldname | Specify a field name that will contain the flag indicating how the values were compared and merged in the output row. |
| Keys to match | Specify the field names that contain the keys on which to generate a match. |
| Values to compare | Specify the field names that contain the values on which to generate a comparison. |
| Get key fields | Click the Get key fields button to populate the Keys to match table with all the fields in the Reference rows origin step. |
| Get value fields | Click the Get value fields button to populate the Values to compare table with all the fields in the Compare rows origin step. |
Examples
The Merge rows – mergs 2 streams of data and add a flag.ktr transformation located in the data-integration/samples/transformations directory illustrates how to use the Merge rows (diff) step.
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.