ORC Input

The ORC Input step reads the fields data from an Apache ORC (Optimized Row Columnar) file into the PDI data stream. You can execute the transformation with PDI or with the Adaptive Execution Layer (AEL), using Spark as the processing engine.
Before using the ORC Input step, you must install and configure the correct shim for your distribution, even if you set your Location to Local. For information on configuring a shim for a specific distribution, see Set up Pentaho to connect to a Hadoop cluster.
AEL considerations
When using the ORC Input step with the Adaptive Execution Layer, the following factor affects performance and results:
- Spark processes null values differently than the Pentaho engine. You will need to adjust your transformation to successfully process null values according to Spark's processing rules.
Options
Enter the following information in the ORC Input step fields:
| Field | Description |
| Step Name | Specify the unique name of the ORC Input step on the canvas. You can customize the name or use the provided default. |
| Location | Indicates the file system or specific cluster where the source file you want to input is located. For the supported file system types, see Using the virtual file system browser in PDI. |
| Folder/File Name |
Specify the fully qualified URL of the source file or folder name for the input fields.
|
Fields
The Fields section contains the following items:
- A Pass through fields from the previous step option that allows you to read the fields from the input file without redefining any of the fields.
- A table defining data about the columns to read from the ORC file.
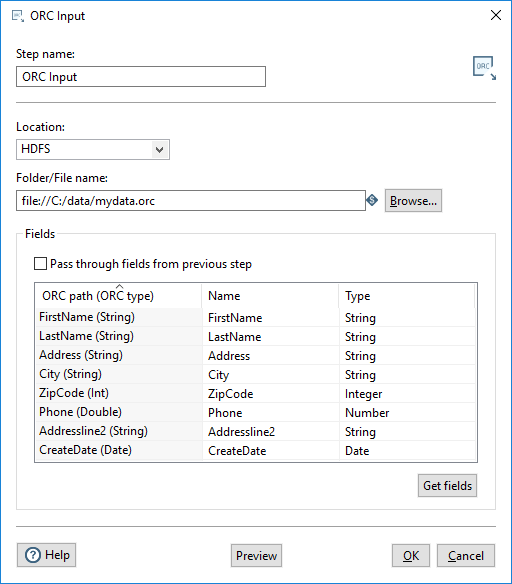
The table in the Fields section defines the fields to read as input from the ORC file, the associated PDI field name, and the data type of the field. Enter the information for the ORC Input step fields as shown in the following table:
| Field | Description |
| ORC path (ORC type) | Specify the name of the field as it will appear in the ORC data file or files, and the ORC data type. |
| Name | Specify the name of the input field. |
| Type | Specify the data type of the input field. |
You can define the fields manually, or you can provide a path to an ORC data file and click Get Fields to populate all the fields. When the fields are retrieved, the ORC type is converted into an appropriate PDI type. You can preview the data in the ORC file by clicking Preview. You can change the PDI type by using the Type drop-down or by entering the type manually.
ORC types
The ORC to PDI data type values are shown in the table below:
| ORC Type | PDI Type |
| String | String |
| TimeStamp | TimeStamp |
| Binary | Binary |
| Decimal | BigNumber |
| Boolean | Boolean |
| Date | Date |
| Integer | Integer |
| Double | Number |
AEL Types
In AEL, the ORC step automatically converts ORC rows to Spark SQL rows. The following table lists the conversion types:
| Orc Type | Spark SQL Type |
| Boolean | Boolean |
| TinyInt | Short |
| SmallInt | Short |
| Integer | Integer |
| BigInt | Long |
| Binary | Binary |
| Float | Float |
| Double | Double |
| Decimal | BigNumber |
| Char | String |
| VarChar | String |
| Timestamp | Timestamp |
| Date | Date |
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.