Parquet Output

The Parquet Output step allows you to map PDI fields to fields within data files and choose where you want to process those files, such as on HDFS. For big data users, the Parquet Input and Parquet Output steps enable you to gather data from various sources and move that data into the Hadoop ecosystem in the Parquet format. Depending on your setup, you can execute the transformation within PDI, or within the Adaptive Execution Layer (AEL) using Spark as the processing engine.
Before using the Parquet Output step, you will need to select and configure the correct shim for your distribution, even if your Location is set to Local. The Parquet Output step requires the shim classes to read the correct data. For information on configuring a shim for a specific distribution, see Connect to a Hadoop cluster with the PDI client.
AEL considerations
When using the Parquet Output step with the Adaptive Execution Layer, the following factor affects performance and results:
- Spark processes null values differently than the Pentaho engine. You will need to adjust your transformation to successfully process null values according to Spark's processing rules.
General
Enter the following information in the transformation step fields.
| Option | Description |
| Step name | Specify the unique name of the Parquet Output step on the canvas. You can customize the name or leave it as the default. |
| Location | Indicates the file system or specific cluster on which the item you want to output can be found. For the supported file system types, see Using the virtual file system browser in PDI. |
| Folder/File name | Specify the location and/or name of the file or folder to write. Click Browse to display the Open File window and navigate to the
file or folder.
|
| Overwrite existing output file | Select to overwrite an existing file that has the same file name and extension. |
Options
The Parquet Output step features two tabs with fields. Each tab is described below.
Fields tab
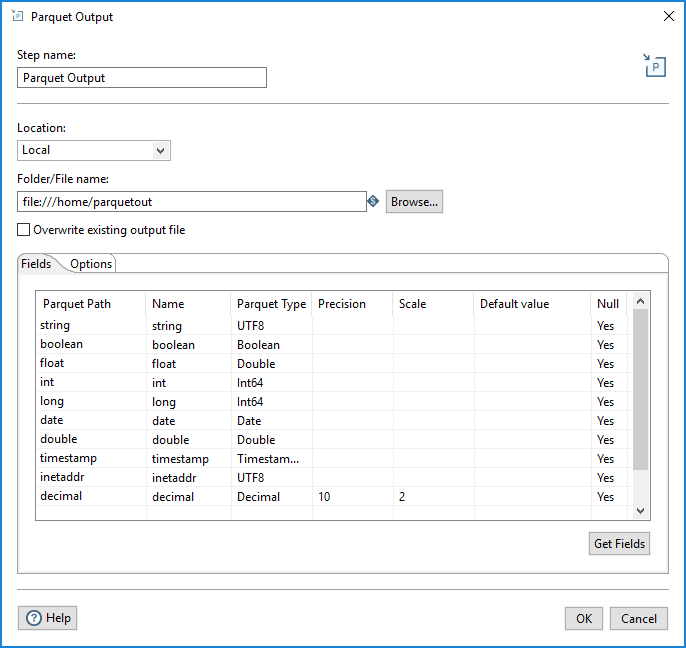
In the Fields tab, you can define properties for the fields being exported. The table below describes each of the options for configuring the field properties.
| Property | Description |
| Parquet Path | Specify the name of the column in the Parquet file. |
| Name | Specify the name of the PDI field. |
| Parquet Type | Specify the data type used to store the data in the Parquet file. |
| Precision | Specify the total number of significant digits in the number (only applies to the Decimal Parquet type). The default value is 20. |
| Scale | Specify the number of digits after the decimal point (only applies to the Decimal Parquet type). The default value is 10. |
| Default value | Specify the default value of the field if it is null or empty. |
| Null | Specify if the field can contain null values. |
You can define the fields manually, or you can click Get Fields to automatically populate the fields. When the fields are retrieved, a PDI type is converted into an appropriate Parquet type, as shown in the table below. You can also change the selected Parquet type by using the Type drop-down or by entering the type manually.
| PDI Type | Parquet Type (non AEL) | Parquet Type (AEL) |
| InetAddress | UTF8 | UTF8 |
| String | UTF8 | UTF8 |
| TimeStamp | TimestampMillis | TimestampMillis |
| Binary | Binary | Binary |
| BigNumber | Decimal | Decimal |
| Boolean | Boolean | Boolean |
| Date | Date | Int96 |
| Integer | Int64 | Int64 |
| Number | Double | Double |
Options tab
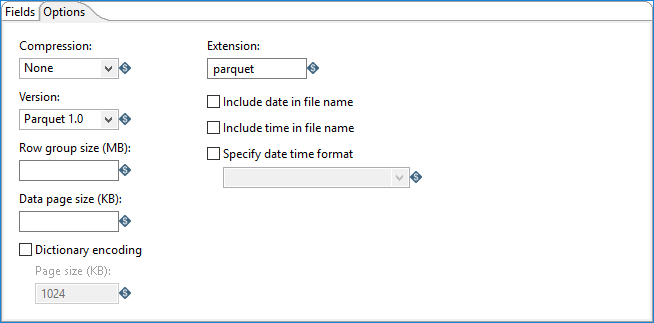
In the Options tab, you can define properties for the file output.
| Option | Description |
| Compression |
Specify the codec to use to compress the Parquet Output file: |
| Version |
Specify the version of Parquet you want to use:
|
| Row group size (MB) | Specify the group size for the rows. The default value is 0. |
| Data page size (KB) | Specify the page size for the data. The default value is 0. |
| Dictionary encoding | Specifies the dictionary encoding, which builds a dictionary of values encountered in a column. The dictionary page is written first, before the data pages of the column. Note that if the dictionary grows larger than the Page size, whether in size or number of distinct values, then the encoding method will revert to the plain encoding type. |
| Page size (KB) | Specify the page size when using dictionary encoding. The default value is 1024. |
| Extension | Select the extension for your output file. The default value is parquet. |
| Include date in file name | Adds the system date to the filename with format
yyyyMMdd (20181231 for example). |
| Include time in file name | Adds the system time to the filename with format
HHmmss (235959 for example). |
| Specify date time format | Specify the date time format using the dropdown list. |
Metadata injection support
All fields of this step support metadata injection. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.