Python Executor

The Python Executor step leverages the Python programming language as part of the data integration pipeline from within PDI. This step helps developers and data scientists take advantage of the strengths of the Python's versatile programming language to develop predictive solutions using existing PDI steps. Instead of writing code to connect to relational databases and Hadoop file systems, and to join and filter data, PDI allows the developer to focus their coding efforts on the data science-driven algorithms.
This step offers several options for execution. You can choose to map upstream data from a PDI input step to generate data or have the Python script generate its own data. You can opt to send all rows to Python at once, or send rows one-by-one.
When you deliver the input row-by-row, the field values of each incoming row are mapped to separate variables containing built-in types, such as numerics, strings, and Booleans. You set the names of these field values which are then available within the Python script.
When you send all rows, the data sent is considered a dataset. Python stores the dataset in a user-specified variable that kicks off your user-defined Python script. You can use the pandas DataFrame, a NumPy array, or the Python list of dictionaries as the data structure for datasets transferred into Python.
Before you begin
Before using the Python Executor step, be aware of the following conditions.
You must install the following Python libraries before using the Python Executor step:
- Pandas (0.18.0 or later) is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language. The pandas DataFrame along with the Series are the two parts of the pandas data structure, a flexible container for lower dimensional data. For example, DataFrame is a container for Series, and Series is a container for scalars. Ultimately, you want to be able to insert and remove objects from these containers in a dictionary-like fashion.
- NumPy (1.14.0 or later) is a library for the Python programming language which adds both robust support for multi-dimensional arrays and matrices, and a large collection of high-level mathematical functions to operate on these arrays. A NumPy array is a table of values, all of the same type, which is indexed by a tuple of positive integers. NumPy arrays can be fast, easy to work with, providing users opportunities to perform calculations across entire arrays.
- Py4J (0.10.2 or later) is a bridge between Python and Java, permitting Python programs running with a Python interpreter to dynamically access Java objects in a JVM. It also allows Java programs to access Python objects.
- Matplotlib (1.5.3 or later) is a plotting library for Python and NumPy.
General
The Python Executor step requires a developer to map to the Python environment, map input, and/or output.
- Step name: Specifies the unique name of the Python Executor step on the canvas. You can customize the name or leave it as the default.
Options
The Python Executor step includes several tabs with fields. Each tab is described below.
Script tab
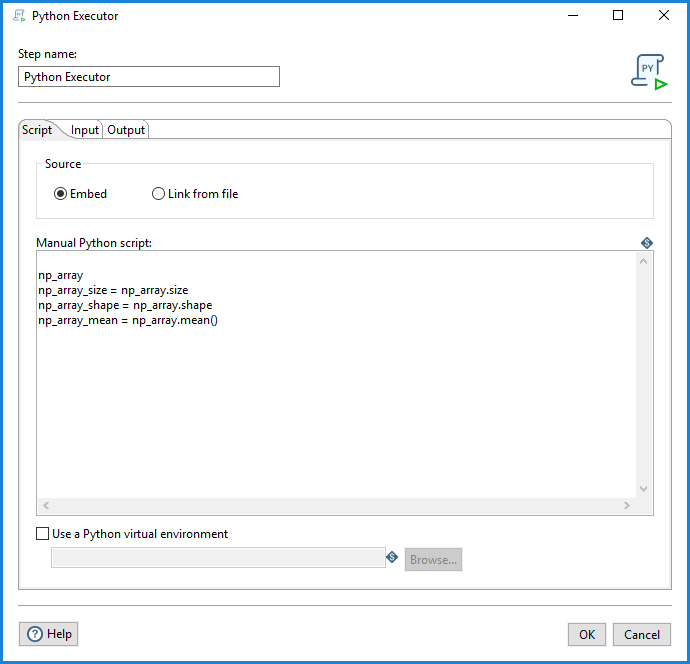
On this tab, decide if you will embed a manual Python script or link to a Python script from a file.
Source panel
The options on this tab vary depending on the script source.
- Embed (default): Select this option to embed the Python script specified in the Manual Python script field. The transformation will run using this Python script.
- Link from file: If you choose this option, you can link out to virtual file systems.
Enter the following information in the fields for the specified source.
| Option | Description |
| Manual Python script (Embed) | Enter the Python script (# python script) you want to embed
for this transformation. |
| Location (Link from file) | Indicates the file system or specific cluster where the python execution file you want to link from is located. For the supported file system types, see Using the virtual file system browser in PDI. |
| File name (Link from file) |
Specify the fully qualified URL of the local Python execution file you want to link from for this transformation. Click Browse to display and enter the path details using
the Virtual File System Browser. This field supports variable injections using
|
| Use a Python virtual environment (check box/field) | Use this option if you have multiple versions of Python installed locally and
you want to select a particular version for this step. Options include:
|
Input tab
Use this tab to make selections for moving data from PDI fields to Python variables. Decide if you want to process your data Row by row (standard PDI behavior) or All rows at once.
The All rows option is commonly used for data frames. A data frame is used for storing data tables and is composed of a list of vectors of equal length. Because data frames combine the behavior of lists and matrices, it is well-suited for the analytical needs of statistical data. For example, data scientists may want to bring in a training dataset before an actual dataset. The training dataset can contain multiple types of data which allows for a broader scope, without the need to join data ahead of time. Now the data scientist can operate with an entire set in the training data frame.
Selecting the Row by row option limits your input to only one type of data, limiting the record of data to a specific time and to what is being read. Selecting the All rows option broadens the depth and scope of your dataset.
Row by row processing
Select the Row by row option to process your data row by row. Each input row will have its fields mapped to the variables as defined in the Mapping table, below. Your Python script will be executed once for each incoming row.

The Mapping table contains the following field properties.
| Field Property | Description |
| Variable | String assigned as a Python variable. |
| Python data type | The Python data type assigned to the variable, such as a string (‘str’), an integer (‘int’), or a floating point (‘float’). For detailed information on data types, see Mapping data types from PDI to Python. |
| PDI field | The PDI field to which you want to map the Python variable. |
| PDI data type | The data type assigned to the PDI field, such as a date, a number, or a timestamp. |
Select the Get fields button to populate the table with fields from the input step(s) in your transformation. If necessary, you can modify your selections.
All rows processing
Select the All Rows option to process all your data at once, for example, using the Python list of dictionaries. This selection is also commonly used for a pandas DataFrame, which contains a broad set of data that does not have to be joined ahead of time.
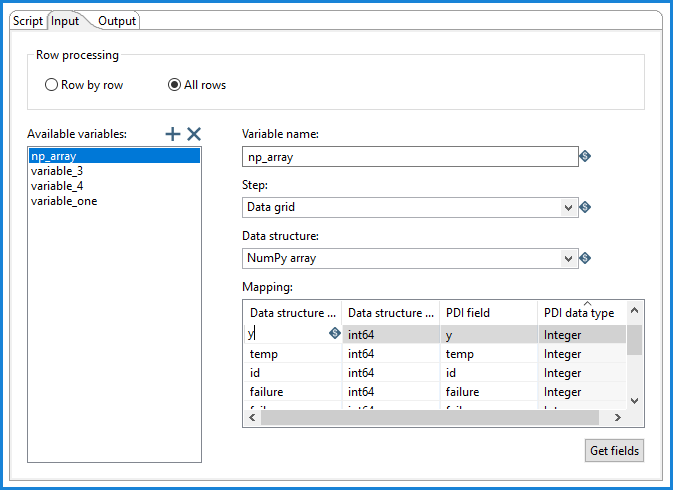
You can select variable names, indicate the input step in the transformations, and specify the data structure.
| Option | Description |
| Available variables | Use the Plus Sign button to add a Python variable to the input mapping for the script used in the transformation. You can remove the Python variable by clicking the X icon. |
| Variable name | Enter the name of the Python variable. The list of Available variables will automatically update. |
| Step | Specify the name of the input step to map from. It can be any step in the parent transformation with an outgoing hop connected to the Python Executor step. |
| Data structure | Specify the data structure from which you want to pull the fields
for mapping. You can select one of the following:
|
The Mapping table contains the following field properties.
| Field Property | Description |
| Data structure field | The value of the Python data structure field to which you want to map the PDI field. |
| Data structure type | The value of the data structure type assigned to the data structure field to which you want to map the PDI field. For detailed information on data types, see Mapping data types from PDI to Python. |
| PDI field | The name of the PDI field which contains the vector data stored in the mapped Python variable. |
| PDI data type | The value of the data type assigned to the PDI field, such as a date, a number, or a timestamp. |
Select the Get fields button to populate the table with fields from the input step(s) in your transformation. If necessary, you can modify your selections.
Mapping data types from PDI to Python
When mapping a data type from PDI to Python, you will want to make the most precise mappings. This table lists the closest PDI data types to the most similar Python data types. Be sure to consider if you are using Pandas dataFrame or NumPy array in this mapping.
| Python Data Structure | PDI Data Type | Python Data Type |
| Pandas dataFrame | BigNumber | float64 |
| Boolean | bool | |
| Date | datetime64[ns] | |
| Integer | int64 | |
| Number | float64 | |
| String | object | |
| Timestamp | datetime64[ns] | |
| NumPy array | BigNumber | float64 |
| Boolean | bool | |
| Integer | int64 | |
| Number | float64 | |
| Basic Python Data Types | BigNumber | float |
| Boolean | bool | |
| Integer | int | |
| Number | float | |
| String | str | |
| Timestamp | datetime |
Output tab
Use this tab to move data from Python variables to PDI fields.
Variable to fields processing
Select the Variable to fields option if your script is intended to produce its output in the form of individual variables, each of which contains a built-in type, such numerics, strings, and Booleans. This option will map the Python variables and their data types to PDI fields and their data types when running the transformation.
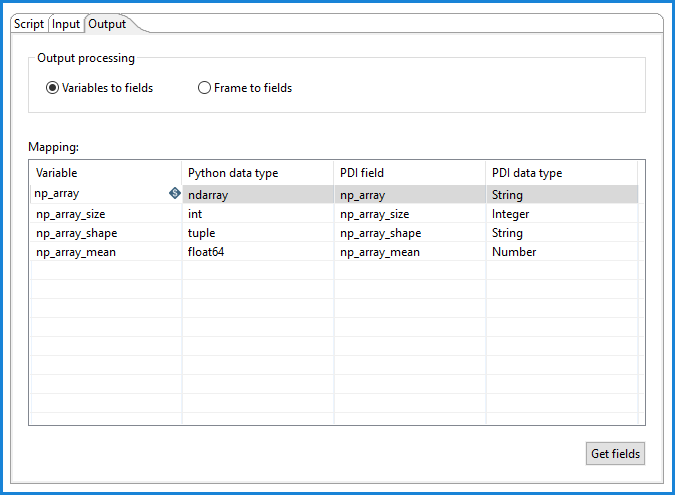
These are the fields in the Mapping table. Select the Get fields button to populate the table with fields from the output step(s) in your transformation.
| Option | Description |
| Variable | The name of the Python variable that will be mapped to a PDI field. |
| Python data type | The value of the data type of the variable. For detailed information on data types, see Mapping data types from Python to PDI. |
| PDI field | The value of the PDI field to which you want to map the Python variable. |
| PDI data type | The value of the data type assigned to the PDI field, such as a date, a number, or a timestamp. |
Frames to fields processing
Select the Frames to fields option if your script produces Python list of dictionaries or a pandas DataFrame as the output. You can then map the data frame fields and types to PDI fields and types when running the transformation.
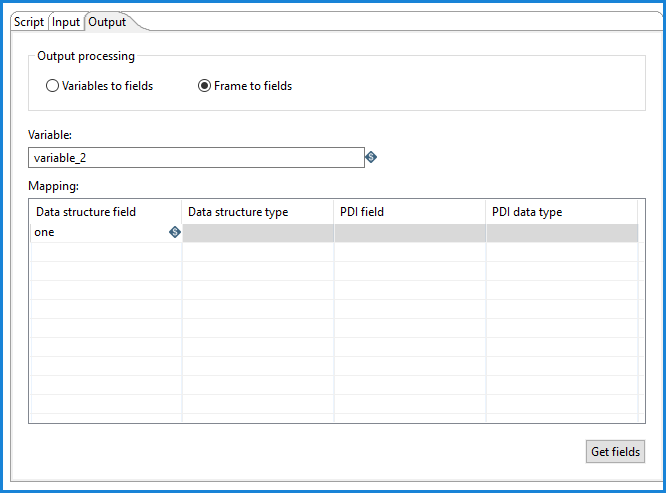
These are the fields in the Mapping table. Select the Get fields button to populate the table with fields from the output step(s) in your transformation. If necessary, you can modify your selections.
| Option | Description |
| Data structure field | The value of the Python data structure field which you want to map to the PDI field. |
| Data structure type | The value of the data structure type assigned to the data structure field which you want to map to the PDI field. For detailed information on data types, see Mapping data types from Python to PDI. |
| PDI field | The value of the PDI field to which you want to map the data structure field. |
| PDI data type | The value of the data type assigned to the PDI field, such as a date, a number, or a timestamp. |
Mapping data types from Python to PDI
When mapping a data type from Python to PDI, you will want to make the most precise mappings. This table lists the closest Python data types to the most most similar PDI data types. Be sure to consider if you are using Pandas dataFrame in this mapping.
| Python Data Structure | Python Data Type | PDI Data Type |
| Pandas dataFrame | bool | Boolean |
| datetime64[ns] | Timestamp | |
| float64 | BigNumber | |
| int64 | Integer | |
| object | String | |
| Basic Python Data Types | bool | Boolean |
| datetime | Timestamp | |
| float | BigNumber | |
| int | Integer | |
| str | String |