Connect to a Hadoop cluster with the PDI client

Creating a connection to the cluster involves setting an active shim, then configuring and testing the connection to the cluster. A shim is an adapter that enables Pentaho to connect to a Hadoop distribution, like Cloudera Distribution for Hadoop (CDH). Making a shim active means it is used by default when you access a cluster. When you first install Pentaho, no shim is active, so this is the first thing you need to do before you try to connect to a Hadoop cluster. Only one shim can be active at a time. The way you make a shim active, as well as the way you configure and test the cluster connection differs by Pentaho component.
After the active shim is set, you must configure, then test the connection. The PDI client (Spoon) has built in tools to help you do this.
Before you begin
Before you begin, make sure that your Hadoop Administrator has granted you permission to access the HDFS directories you need. This typically includes your home directory as well as any other directories you need to do your work. Your Hadoop Administrator should have already configured Pentaho to connect to the Hadoop cluster on your computer. For more details on how to do this, see the Set Up Pentaho to Connect to a Hadoop Cluster article. You also need to know these things:
- Distribution and version of the cluster (e.g. Cloudera Distribution 5.4)
- IP Addresses and Port Numbers for HDFS, JobTracker, and Zookeeper (if used)
- Oozie URL (if used)
To connect Pentaho to a Hadoop cluster you will need to perform two tasks:
Procedure
Set the Active Shim in the PDI client
Configure and Test the Cluster Connection
Set the active shim in the PDI client
Set the active shim when you want to connect to a Hadoop cluster the first time, or when you want to switch clusters. Only one shim can be active at a time.
Procedure
Select Hadoop Distribution from the Tools menu.
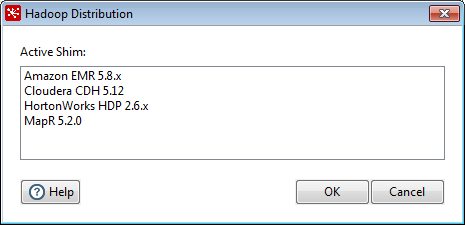
In the Hadoop Distribution window, select the Hadoop distribution you want.
Click OK.
Stop, then restart the PDI client.
Configure and test the cluster connection
Configured connection information is available for reuse in other steps and entries. Whether you are connected to the Pentaho Repository when you create the connection determines who can reuse it.
- If you are connected to the Pentaho Repository when you create the connection, you and other users can reuse the connection.
- If you are not connected to the Pentaho Repository when you create the connection, only you can reuse the connection.
Open the Hadoop Cluster window
Connection settings are set in the Hadoop Cluster window. You can get to the settings from these places:
- View tab in a transformation or job
- Repository Explorer window
View tab
Procedure
In the PDI client, create a new job or transformation or open an existing one.
Click the View tab.
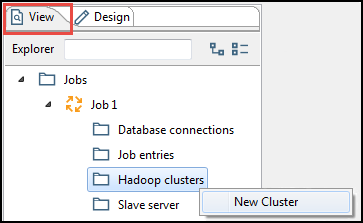
Right-click the Hadoop clusters folder, then click New.
The Hadoop Cluster window appears.
Results
Repository Explorer
Procedure
In the PDI client, connect to the repository where you want to store the transformation or job.
From the Tools menu, choose to open the Repository Explorer window.
Click the Hadoop clusters tab.
Click the New button.
The Hadoop Cluster window appears.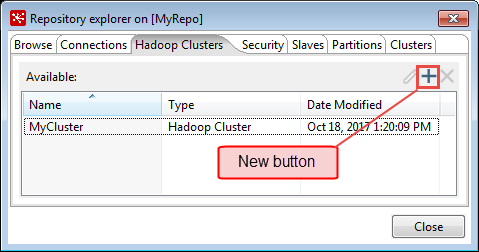
Results
Configure and test connection
Once you have opened the Hadoop Cluster window from a step or entry, the View tab, or the Repository Explorer window, configure the connection.
Procedure
Enter information in the Hadoop Cluster window.
You can get most of the information you need from your Hadoop administrator. As a best practice, use Kettle variables for each connection parameter value to mitigate risks associated with running jobs and transformations in environments that are disconnected from the repository.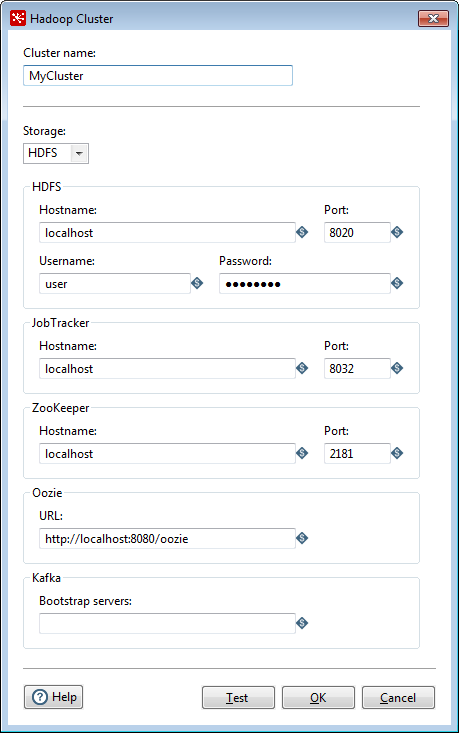
Option Description Cluster Name Name that you assign the cluster connection. Storage Specifies the type of storage you want to use for this connection. Use the drop-down box to select one of the following:
HDFS
Hadoop Distributed File System, which is typically used for connecting to a Hadoop cluster. This is the default storage selection.
MapR
MapR Converged Data Platform. When selected, the fields in the storage and JobTracker sections are disabled because these parameters are not needed to configure MapR.
WASB
Windows Azure Storage Blob, which is only available for connecting to Azure HDInsight.
NoteIf you select MapR storage, the fields in the MapR and Job Tracker sections of the Hadoop Cluster dialog box are disabled.Hostname (in selected storage section) Hostname for the HDFS or WASB node in your Hadoop cluster. Port (in selected storage section) Port for the HDFS or WASB node in your Hadoop cluster.
NoteIf your cluster has been enabled for high availability (HA), then you do not need a port number. Clear the port number.Username (in selected storage section) Username for the HDFS or WASB node. Password (in selected storage section) Password for the HDFS or WASB node. Hostname (in JobTracker section) Hostname for the JobTracker node in your Hadoop cluster. If you have a separate job tracker node, type in the hostname here. Port (in JobTracker section) Port for the JobTracker in your Hadoop cluster. Hostname (in ZooKeeper section) Hostname for the Zookeeper node in your Hadoop cluster. Supply this only if you want to connect to a Zookeeper service. Port (in Zookeeper section) Port for the Zookeeper node in your Hadoop cluster. Supply this only if you want to connect to a Zookeeper service. URL (in Oozie section) Oozie client address. Supply this only if you want to connect to the Oozie service. Bootstrap servers (in Kafka section) The host/port pair(s) for the initial connection to the Kafka cluster. Use a comma-separated list for multiple servers, for example, ‘host1:port1,host2:port2’. While you do not need to include all the servers used for Kafka, you may want to include more than one in case a server is down. Click the Test button.
Test results appear in the Hadoop Cluster Test window. If you have problems, see Troubleshoot Connection Issues to resolve the issues, then test again.
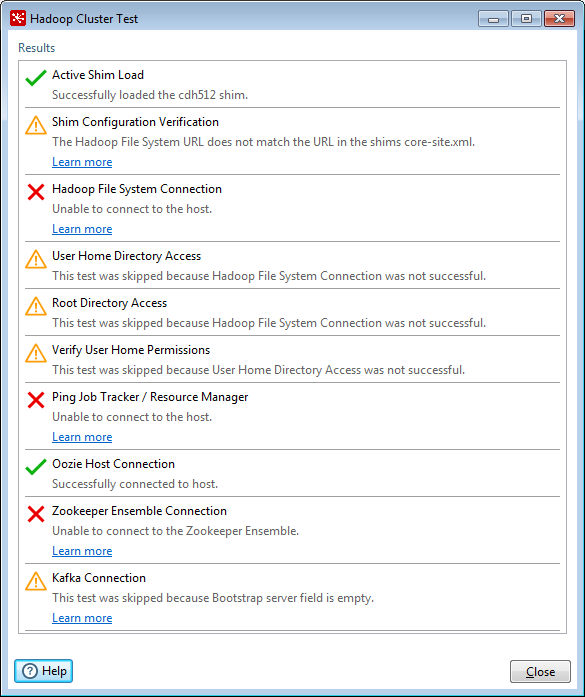
If there are no more errors, congratulations! The connection is properly configured. Click the Close button to the remaining Hadoop Cluster Test window.
When complete, click the OK button to close the Hadoop Cluster window.
Next steps
Manage existing Hadoop cluster connections
Once cluster connections have been created, you can manage them.
- Edit Hadoop cluster connections
- Duplicate Hadoop cluster connections
- Delete Hadoop cluster connections
Edit Hadoop cluster connections
How updates occur depend on whether you are connected to the repository.
If you are connected to a repository
Hadoop cluster connection changes are picked up by all transformations and jobs in the repository. The Hadoop cluster connection information is loaded during execution unless it cannot be found. If the connection information cannot be found, the connection values that were stored when the transformation or job was saved are used instead.
If you are not connected to a repository
Hadoop cluster connection changes are only picked up by your local (file system) transformations and jobs. If you run these transformations and jobs outside of Kettle, they will not have access to the Hadoop cluster connection, so a copy of the connection is saved as a fallback. Note that changes to the Hadoop cluster connection are not updated in any transformations or jobs for the purpose of fallback unless they are saved again.
You can edit Hadoop cluster connections in two places:
- View tab
- Repository Explorer window
View tab
Procedure
Click the Hadoop Clusters folder in the View tab.
Right-click a connection, then select Edit.
The Hadoop Cluster window appears.Make changes, then click Test.
Click the OK button.
Repository Explorer
To edit Hadoop cluster connection from the Repository Explorer window, complete these steps:
Click the Hadoop Clusters tab in the Repository Explorer window.
Select a connection, then click Edit.
The Hadoop cluster window appears.Make changes, then click Test.
Click OK.
Duplicate a Hadoop cluster connection
You can only duplicate or clone a Hadoop cluster connection in the View tab of the PDI client. To duplicate or clone a cluster connection, complete these steps:
Click the Hadoop clusters folder in the View tab.
Right-click a connection and select Duplicate.
The Hadoop cluster window appears.Enter a different name in the Cluster Name field.
Make changes, then click Test.
Click OK.
Delete a Hadoop cluster connection
Deleted connections cannot be restored. But, you can still run transformations and jobs that reference them because deleted connections details are stored in the transformation and job metadata files.
You can delete Hadoop cluster connections in two places:
- View tab
- Repository Explorer window
View tab
To delete Hadoop cluster connection in a transformation or job, complete these steps:
Procedure
Click the Hadoop clusters folder in the View tab.
Right-click a Hadoop cluster connection and select Delete.
A message appears asking whether you really want to delete the connection.Click Yes.
Repository Explorer
To delete Hadoop cluster connections from the Repository Explorer window, complete these steps:
Procedure
Connect to the Repository Explorer.
Click the Hadoop Clusters tab.
Select a Hadoop cluster connection, then click Delete.
A message appears asking if you really want to delete the Hadoop cluster connection.Click Yes.
Connect other Pentaho components to a cluster
For information on connecting other Pentaho components to a cluster, refer to the following: