Streaming analytics

With streaming analytics, you can constantly perform statistical analysis while moving within a data stream.
You can use streaming analytics to manage, monitor, and record real-time analytics of live streaming data so you can quickly extract the necessary information from big volumes of data to react to changing conditions in real time. Businesses generate continuous data from the following sources:
- Log files generated by customers using mobile or web applications, e-commerce purchases, and in-game player activity.
- Telemetry, such as data from connected devices, sensors, and instrumentation in data centers.
- Data collected from social networks, financial trading systems, and geospatial services.
Once collected, the streaming data values from these sources will be processed sequentially and incrementally on a record-by-record basis or a time-based sliding window. Ingesting a window of values allows for both processing and analysis of the data, such as through correlating, aggregating, filtering, and sampling. The following figure is an example of a time-based sliding window.
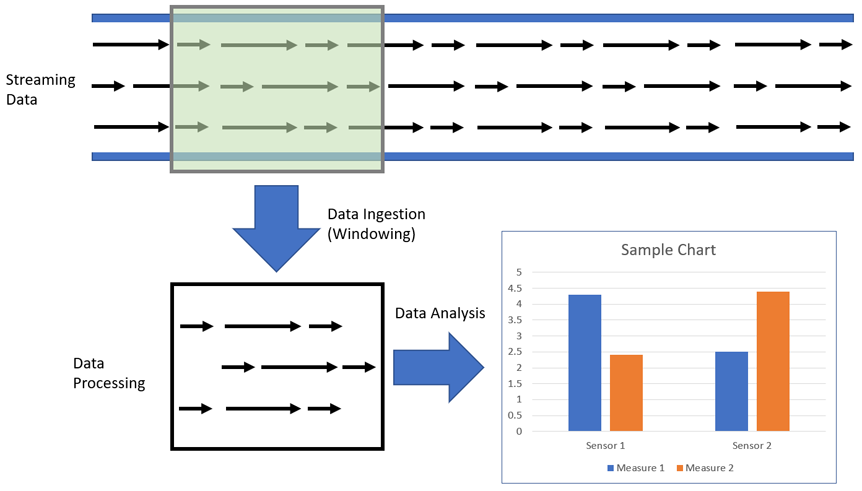
Companies use this information to gain insights into their business and customer activity, such as service usage for billing rates, server activity, website clicks, and geo-locations of devices, people, or physical goods. For example, businesses can track changes in public sentiment on their brands and products by continuously monitoring and analyzing social media streams, and then quickly respond as needed.
The Internet of Things (IoT) also creates large stores of streaming data. Smart objects, such as cars, appliances, and electronic devices, produce data points throughout their operations, activities, and behaviors. Businesses can analyze these points in the data streams to reduce operating costs, improve product reliability, or optimize usage models. For example, you can monitor equipment performance based on its data output. Continuous pattern detection finds anomalies referred to as data gaps. These gaps help to pinpoint when to buy material, plan modifications, and staff personnel.
IoT devices and communication protocols, including text data and transmissions from both legacy and modern equipment sensors, for example, create streaming data of various formats. These multiple formats must be normalized, cleansed, and standardized to process individual events in-memory. Data must be continually corrected and assessed in windows before analysis.
Before you can use streaming analytics, you must ingest the data into PDI as it is received. Within PDI, you can also send event messages to trigger a process of Extract, Transform, and Load (ETL) alerts.
Get started with streaming analytics in PDI
Pentaho Data Integration (PDI) products are designed to work as if data flows like running water. You can think of PDI as a series of pipes through which water flows and is joined and mixed with other flows. No matter how big the source, the water keeps flowing, such that all the data will be processed if the data keeps flowing. The size of the “pipe” in PDI is directly linked to the number of data records and to the amount of memory needed to hold all those records. The key to successfully transforming your data with high performance is to understand which PDI steps may increase and speed up the flow.
You can develop a PDI transformation that is always waiting for new data. All the steps continue running, awaiting new data. In this transformation, the input steps ingest data records in PDI from the stream. Once ingested, you can process the data to refine it. After processing, you can push it back into the stream or retain it for analysis.
Data ingestion
Data is ingested into PDI by pulling messages from a stream into a transformation through a specified window. A consumer step in a parent transformation pulls the data into PDI, then runs a child sub-transformation, which executes according to the window parameters. The window creates a continuous stream of records in near real-time.
In the consumer step itself, you can define the number of messages to accept for processing, as well as the specific data formats to stream data. You can set up this step to collect events, monitor alerts, and track user consumption of data streams. Additionally, you can select a step in the child transformation to stream records back to the parent transformation, which passes records downstream to any other steps included within the same parent transformation.
The following consumer steps ingest streaming data into PDI from the specified sources:
Advanced Message Queuing Protocol brokers
Apache ActiveMQ Java Messaging Service server or IBM MQ middleware
Kafka server
Amazon Kinesis Data Streams service
Message Queuing Telemetry Transport broker or clients
In PDI, the data stream window is defined by either duration (in milliseconds) or number of rows. The window of data is created when either the duration or number of rows occur. For example, if the duration is set to 1000 milliseconds and the number of rows is 1000, windows of data are created whenever time intervals of 1000 milliseconds are reached or 1000 rows have been received. If you set either duration or number of rows to 0 (zero), PDI will ignore that parameter. For example, if duration is set to 1000 milliseconds and the number of rows is zero, windows are created only every 1000 milliseconds.
You can specify the maximum number of these batches used to collect records at the same time. However, you should only specify a maximum number of these concurrent batches when your consumer step cannot keep pace with the speed at which the data is streaming. Your computing environment must have adequate CPU and memory for this implementation. An error will occur if your environment cannot handle the maximum number of concurrent batches specified.
Depending on your setup, you can run the transformation within PDI or using Spark within the Adaptive Execution Layer (AEL) as the execution engine, which is set in the Run Options dialog box. The Spark engine executes the child transformation by duration only, and not by the number of rows.
Before using a consumer step with big data, you must set up Pentaho to connect to a Hadoop cluster.
Data processing
Once the data stream is ingested through windowing, you can process these windows in your child transformation. Use the child transformation to adjust the data and handle event alerts as needed. After processing, you can either load the windowed data into various outputs or publish it back into the data message stream. You can publish data back into the message stream by using the following producer steps for your specified target:
- AMQP Producer: Advanced Message Queuing Protocol brokers
- JMS Producer: Apache ActiveMQ Java Messaging Service server or the IBM MQ middleware
- Kafka Producer: Kafka server
- Kinesis Producer: Support for pushing data to a specific region and stream located within the Amazon Kinesis Data Streams service
- MQTT Producer: Message Queuing Telemetry Transport broker or clients
You can also use the data streaming window to capture data for analysis. Streaming Pentaho data services can be created from output steps in the child transformation. You can use CTools to create dashboards using these services as data sources. See Creating a regular or streaming Pentaho Data Service and Create a dashboard that uses a streaming service as a data source for more information.
Once started, streaming data transformations run continuously. You can stop these transformations using the following tools:
- The stop option in the PDI client.
- The Abort step in either the parent or child transformation.
- Restarting the Pentaho or Spark execution engine.