Spark Tuning

Spark tuning is the customization of PDI transformation and step parameters to improve the performance of running your PDI transformations on Spark. These parameters affect memory, cores, and instances used by the Spark engine. These Spark parameters include:
- Application tuning parameters which are transformation parameters for working with PDI transformations on Spark.
- Spark tuning options which are parameters for a specific PDI step.
Use the Spark tuning options to customize Spark parameters within a PDI step to further refine how your transformation runs. For example, if your KTR contains many complex computations, you can adjust the Spark tuning options for a PDI step to increase performance and decrease run times when executing your transformation.
This article provides a reference for the step-level Spark tuning options available in PDI. The Spark tuning categories, options, and applicable steps are listed below. For more information about the Spark tuning workflow, see About Spark tuning in PDI.
Spark tuning options for PDI steps include the following categories:
Set these options for data persistence, repartitioning, and coalesce. Tune these options to help you save downstream computation, such as reducing the amount of possible recalculations after wide Spark transformations. Options include partitioning data, persisting data, and caching data.
Set this broadcast join option to push datasets out to the executors which can reduce shuffling during join operations.
Set these options to specify the number of JDBC connections, including partitioning attributes.
Set these options for partitioning management, including bucketing file writes.
Audience and prerequisites
Spark tuning features are intended for ETL developers who have a solid understanding of PDI, Spark, and your system's cluster resources. For effective Spark tuning, you need to know how a transformation uses your resources, including both your environment and data size. PDI steps vary in their resource requirements, so you should tune the Spark engine to meet the needs of each transformation.
To use the Spark tuning features, you need access to the following information:
- Cluster resources
- Amount of resources available to the Spark engine during execution, including memory allotments and number of cores.
- Size of data.
You may want to consult your cluster administrator, who can perform the following tasks:
- Monitor cluster resources on the YARN Resource Manager.
- Manage Spark execution resources on the Spark History Server.
Opening the PDI step Spark tuning options
You can access the Spark tuning options from a PDI step by right-clicking on
the step in the canvas and selecting Spark tuning parameters from the
menu. 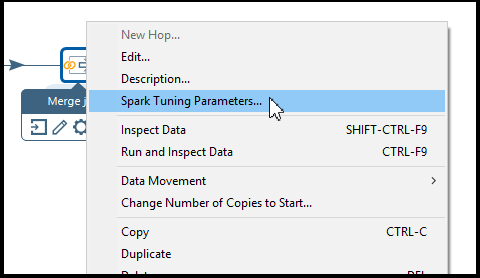
The Spark tuning parameters dialog box appears. Click in
the column to view the Spark tuning options available for that step in the dialog box. These
options vary from step to step, depending on the scope of the step. 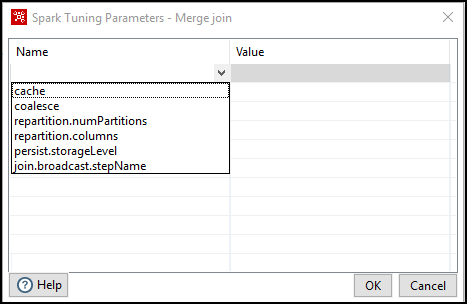
Setting PDI step Spark tuning options
Dataset tuning options
The Dataset tuning options include partitioning data and persisting or caching data, which can save downstream computation.
Effective memory management is critical for optimizing performance when running PDI transformations on the Spark engine. The Spark tuning options provide the ability to adjust Spark defaults settings and customize them to your environment. Depending on the application and environment, specific tuning parameters may be adjusted to meet your performance goals.
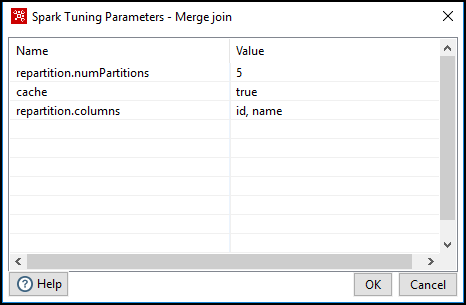
One of the most important capabilities in Spark is persisting (or caching) a Dataset in memory across operations. You can define partitioning and you can apply cache or persist.storageLevel or none.
The following table describes common data formats used by PDI transformation steps and job entries:
| Option | Description | Value type | Example value |
| cache | Persist the Dataset with the default storage level
(MEMORY_AND_DISK). See the Spark API documentation for more
information. | Boolean | true/false |
| coalesce |
Returns a new Dataset that has exactly Note: In PDI, this option must be used with the reparatition.numPartitions option. | Boolean | true/false |
| repartition.numPartitions |
Returns a new Dataset partitioned by the given partitioning value
into Note: In PDI, this option can be used with repartition.columns. Note: When coalesce is set to
| Integer | 5 |
| repartition.columns |
Returns a new Dataset partitioned by the given Dataset columns, and only works with the repartition.numPartition option. The resulting Dataset is hash partitioned by the given columns. See the Spark API documentation for more information. Note: In PDI, the step logs an error if an invalid column is entered. | Comma separated strings | column1, column2 |
| persist.storageLevel |
Each persisted Dataset can be stored using a different storage
level. These levels are set by passing a See the Spark API documentation to view more information about RDD persistence, the full set of storage levels, and how to choose a storage level. | Spark Storage Level | MEMORY_ONLY |
The following examples show you how the Dataset tuning options work with a given set of values in a PDI step:
| Example of step tuning options and values | Resulting Spark API call |
| dataset.repartition( 5, Column[]{ “id”, “name”}
).cache() |
| dataset.coalesce( 15 ).persist( StorageLevel.IN_MEMORY
) |
Steps using Dataset tuning options
Many of the PDI transformation steps feature the Dataset tuning options. For the full list of steps, see Steps using Dataset tuning options.
Join tuning options
Use the broadcast join tuning option instead of the hash join to optimize join queries when the size of one side of the data is below a specific threshold. Customizing your broadcast join can efficiently join a large table with small tables, such as a fact table with a dimensions table, which can reduce the amount of data sent over the network.
| Option | Description | Value type | Example value |
| join.broadcast.stepName | Marks a DataFrame as small enough for use in broadcast joins. See the Spark API documentation for more information. | String | stepName |
Steps using join tuning options
You can use the join tuning options with the following steps:
| Step category | Step name |
| Joins |
|
DataframeWriter tuning options
Partitioning management is a critical factor in optimized performance because
too few partitions may result in underused resources and too many partitions may result in
too many resources for managing small tasks. Partitioning your data more evenly helps avoid
these problems. Because partitioning is pushed down to the data in the output files during
the DataFrameWriter .save() call, repartitioning occurs when writing
files.
| Option | Description | Value type | Example value |
| write.partitionBy.columns | Partitions the output by the given columns on the file system. See the Spark API documentation for more information. | Comma separated strings | column1, column2 |
| write.bucketBy.columns | Buckets the output by the given columns. See the Spark API documentation for more information. | Comma separated strings | column1, column2 |
| write.sortBy.columns | Sorts the output in each bucket by the given columns. See the Spark API documentation for more information. | Comma separated strings | column1, column2 |
| write.bucketBy.numBuckets | Buckets the output by the given columns. See the Spark API documentation for more information. | Integer | 5 |
Steps using DataframeWriter tuning options
You can use the DataFrameWriter tuning options with the following steps:
| Step category | Step name |
| Big Data |
|
JDBC tuning options
Spark is a massive parallel computation system that can run on many nodes, processing hundreds of partitions at a time, but when working with SQL databases, you may want to customize processing to reduce the risk of failure. You can specify the number of concurrent JDBC connections, numeric column names, minimal value to read, and maximum value to read. Spark then reads data from the JDBC partitioned by a specific column and partitions the data by the specified numeric column, producing parallel queries when applied correctly. If you have a cluster installed with Hive, the JDBC tuning options can improve transformation performance.
The read-jdbc parameter constructs a
DataFrame representing the database table accessible via a JDBC URL named
table. Partitions of the table are retrieved in parallel based on the parameters passed to
this function. See the Spark API documentation for more information.
| Option | Description | Value type | Example value |
| read.jdbc.columnName | The name of a column of integral type that will be used for partitioning. | String | column1 |
| read.jdbc.lowerBound | The minimum value of columnName used to decide
partition stride. This option works with
read.jdbc.columnName. | Any value | |
| read.jdbc.upperBound | The maximum value of columnName used to decide
partition stride. This option works with
read.jdbc.columnName. | Any value | |
| read.jdbc.numPartitions | The number of partitions. This, along with
lowerBound (inclusive), upperBound
(exclusive), form partition strides for generated WHERE clause expressions used to
split the column columnName evenly. When the input is less than
1, the number is set to 1. | Integer | 5 |
Steps using JDBC tuning options
You can use the JDBC tuning options with the following step:
| Step category | Step name |
| Input |
|