Use Kerberos with Spark Submit

This article explains how to execute Spark Submit jobs on secure Cloudera Hadoop clusters version 5.7 and later using Kerberos authentication. Spark jobs can be submitted to the secure clusters by adding keytab and principal utility parameter values to the job. These values are what enable Kerberos authentication for Spark.
Prerequisites
The following prerequisites must be completed before running the Spark jobs:
- A Spark client must be installed, Refer to the article Spark Submit for information on installing and configuring the Spark client.
- The cluster must be secured with Kerberos, and the Kerberos server used by the cluster must be accessible to the Pentaho Server.
- The Pentaho computer must have Kerberos installed and configured as explained in Set Up Kerberos for Pentaho.
Spark Submit entry properties
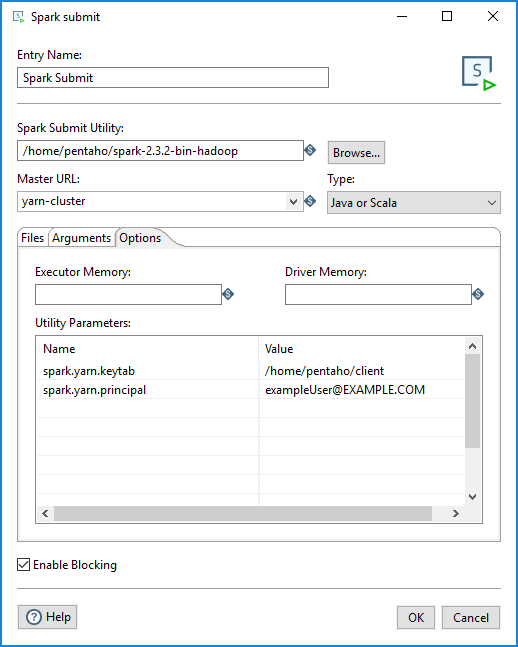
Configure your job setup with the parameters in the following table. For additional details, see Spark Submit.
| Parameter | Value |
| Entry Name | Specify the name of the entry. You can customize this, or leave it as the default. |
| Spark Submit Utility | Specify the name of the script that launches the Spark job, which
is the batch/shell file name of the underlying spark-submit tool. For example,
Spark2-submit. |
| Master URL | Choose a master URL for the cluster from the drop-down:
|
| Type |
Select the file type of the Spark job you want to submit. Your job can be written in Java, Scala, or Python. The fields displayed in the Files tab will depend on what language option you select. Python support on Windows requires Spark version 2.3.x or higher. |
| Utility Parameters |
Specify the Name and Value of optional Spark configuration parameters associated with the spark-defaults.conf file. Add the following name and value pairs:
|
| Enable Blocking | Select Enable Blocking to have the Spark Submit entry wait until the Spark job finishes running. If this option is not selected, the Spark Submit entry proceeds with its execution once the Spark job is submitted for execution. Blocking is enabled by default. |
Authentication via password is not supported.