Using Spark Submit

You can use the Spark Submit job entry, along with an externally developed Spark execution script, to run Spark jobs on your YARN clusters. If you want to run transformations without the need to develop a Spark execution script, then refer to the run configuration information about using the Spark engine in AEL.
The following instructions explain how to use the Spark Submit entry in PDI to run a Spark job. To learn how to execute Spark Submit jobs on secure Cloudera Hadoop clusters, see Use Kerberos with Spark Submit.
Modify the sample Spark Submit job
The following example demonstrates how to use PDI to submit a Spark job.
Open and rename the job
To copy files in these instructions, use either the Hadoop Copy Files job entry or Hadoop command line tools. For an example of how to do this using PDI, check out our tutorial at http://wiki.pentaho.com/display/BAD/Loading+Data+into+HDFS.
Perform the following steps to modify the sample Spark job and understand how a Spark Submit entry works in PDI:
Procedure
Copy a text file that contains words that you would like to count to the HDFS on your cluster.
Start the PDI client.
Open the Spark Submit.kjb job, which can be found in the design-tools/data-integration/samples/jobs/Spark Submit folder.
Select , and then rename and save the file as Spark Submit Sample.kjb.
Results
The Spark Submit Sample.kjb file is saved to the jobs folder.
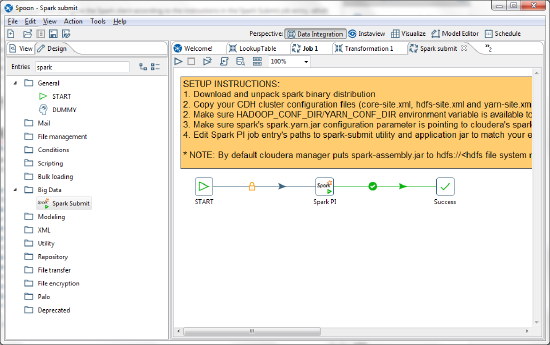
Run the sample Spark Submit job
Procedure
Open the Spark PI job entry.
Spark PI is the name given to the Spark Submit job entry in the sample.Indicate the path to the spark-submit utility in the Spark Submit Utility field.
It is located where you installed the Spark client.Indicate the path to your Spark examples JAR file (either the local version or the one on the cluster in the HDFS) in the Application Jar field.
The Word Count example is in this JAR.In the Class Name field, add the following: org.apache.spark.examples.JavaWordCount.
We recommend that you set the Master URL to yarn-client.
To read more about other execution modes, see the Submitting Applications article in the Spark documentation.In the Arguments field, indicate the path to the file you want to run Word Count on.
Click OK.
Save the job.
Run the job.
Results