Using the Hadoop File Input step on the Pentaho engine

If you are running your transformation on the Pentaho engine, use the following instructions to set up the Hadoop File Input step.
General
Enter the following information in the transformation step name field.
- Step Name: Specifies the unique name of the transformation step on the canvas. The Step Name is set to Hadoop File Input by default.
Options
The Hadoop File Input step features several tabs with fields for setting environments and defining results. Each tab is described below.
File tab
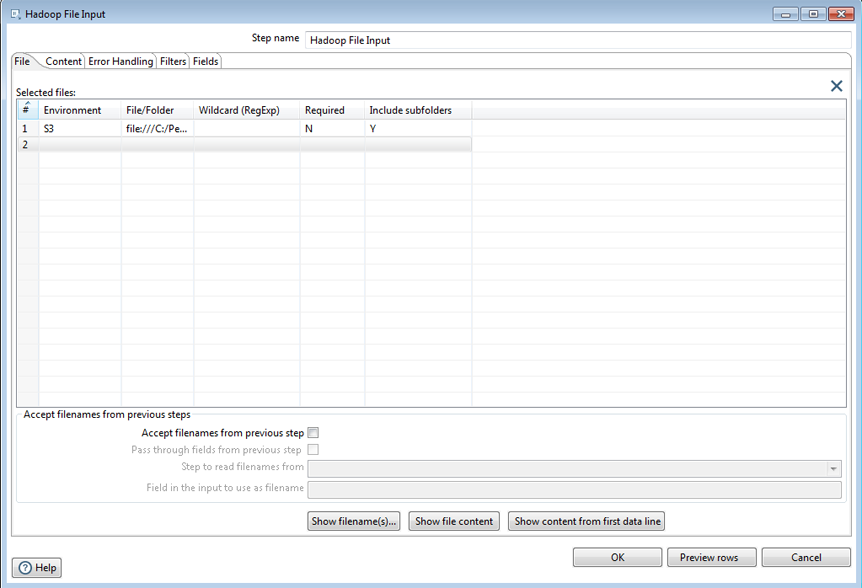
In this tab, specify the environment and other details for the file you want to input.
| Option | Description |
| Environment |
Indicate the file system or specific cluster on which the item you want to input can be found. Options are:
|
| File/Folder | Specify the location and/or name of the text file to read. Click the Ellipsis (...) button to navigate to the source file or folder in the VFS browser. |
| Wildcard (RegExp) | Specify the regular expression you want to use to select the files in the directory specified in the File/Folder field. For example, you may want to process all files that have a .txt output. See Selecting a file using regular expressions for examples of regular expressions. |
| Required | Indicate if the file is required. |
| Include subfolders | Indicate if subdirectories (subfolders) are included. |
Accepting file names from a previous step

The Accept filenames from previous steps section in the File tab provides flexibility in combination with other steps, such as Get File Names. You can specify your file name and pass it to this step. Using this method, the file name can come from any source, such as a text file or database table.
| Option | Description |
| Accept file names from previous steps | Select the check box to get file names from previous steps. |
| Pass through fields from previous step | Select the check box to get field information from previous steps. |
| Step to read file names from | Enter the name of the step from which to read the file names. |
| Field in the input to use as file name | Text File Input looks in this step to determine which file names to use. |
Show action buttons

When you have entered information in the File tab fields, select one of the following action buttons:
| Button | Description |
| Show filename(s) | Select to display a list of all files that are loaded based on the current selected file definitions. |
| Show file content | Select to display the raw content of the selected file. |
| Show content from first data line | Select to display the content from the first data line for the selected file. |
Selecting a file using regular expressions
Use the Wildcard (RegExp) field in the File tab to search for files by wildcard in the form of a regular expression. Regular expressions are more sophisticated than using * and ? wildcards. This table describes several examples of regular expressions.
| File Name | Regular Expression | Files Selected |
| /dirA/ | .userdata.\.txt | Find all files in /dirA/ with names containing userdata and ending with .txt |
| /dirB/ | AAA.\* | Find all files in /dirB/ with names that start with AAA |
| /dirC/ | \[ENG:A-Z\]\[ENG:0-9\].\* | Find all files in /dirC/ with names that start with a capital and followed by a digit (A0-Z9) |
Open file
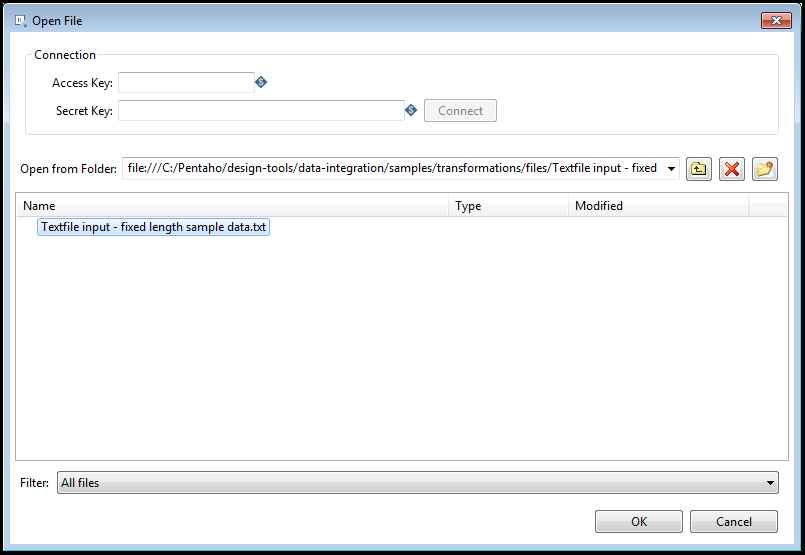
Procedure
In the Connection section, fill in the following options.
Option Description Access Key Enter the user name needed to access the S3 file system. This option only appears if you select S3 in the Source Environment field in the Hadoop File Input window. Secret Key Enter the password needed to access the S3 file system. This option only appears if you select S3 in the Source Environment field in the Hadoop File Input window. Open from Folder Indicates the path and name of the directory you want to browse. This directory becomes the active directory. In the Open from Folder field, navigate to the path and name of the directory you want to browse. This directory becomes the active directory.
Use the following options to view and modify the active directory selected in the Open from Folder field:
Option Description Up One Level icon Click this button to display the parent directory of the active directory shown in the Open from Folder field. Delete icon Click this button to delete a folder from the active directory. Create Folder icon Click this button to create a new folder in the active directory. Name/Type/Modified Display the active directory, which is the one that is listed in the Open from Folder field. The file type and last modified date display to the right of the folder or file in the Name list. Filter Apply a filter to the results displayed in the active directory contents. Click OK to continue, or Cancel to return to the File tab without saving your selections.
Content tab
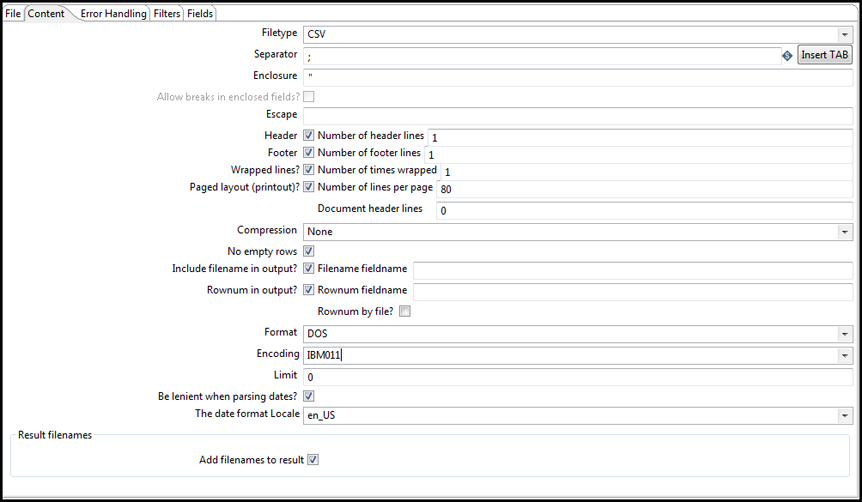
In the Content tab, you can specify the format of the text files that are being read.
| Option | Description |
| Filetype | Select either CSV or Fixed length. Based on this selection, the PDI client launches a different helper GUI when you click Get Fields in the Fields tab. |
| Separator | One or more characters that separate the fields in a single line of text. Typically, this is a semicolon ( ; ) or tab. |
| Enclosure | Some fields can be enclosed by a pair of strings to allow separator characters in fields. The enclosure string is optional. |
| Allow breaks in enclosed fields | Not implemented. |
| Escape | Specify an escape character (or characters) if you have these types of characters in your data. If you have a backslash ( / ) as an escape character, the text Not the nine o\'clock news (with a single quote \[ ' \] as the enclosure) is parsed as Not the nine o'clock news. |
| Header & Number of header lines | Select if your text file has a header row (first lines in the file). You can specify the number of times the header line appears. |
| Footer & Number of footer lines | Select if your text file has a footer row (last lines in the file). You can specify the number of times the footer row appears. |
| Wrapped lines & Number of times wrapped | Select if you work with data lines that have wrapped beyond a specific page limit. Headers and footers are never considered wrapped. |
| Paged layout (printout), Number of lines per page, & Document header lines | Use these options as a last resort when working with texts meant for printing on a line printer. Use the number of document header lines to skip introductory texts and the number of lines per page to position the data lines. |
| Compression | Use this field if your text file is in a ZIP or GZIP archive. Only the first file in the archive is read. |
| No empty rows | Select if you do not want to send empty rows to the next steps. |
| Include filename in output? | Select if you want the file name to be part of the output. |
| Filename fieldname | Enter the name of the field that contains the file name. |
| Rownum in output? | Select if you want the row number to be part of the output. |
| Rownum fieldname & Rownum by file? | Enter the name of the field that contains the row number. |
| Format | Can be either DOS, UNIX, or mixed. UNIX files have lines that are terminated by line feeds. DOS files have lines separated by carriage returns and line feeds. If you specify mixed, no verification is done. |
| Encoding & Limit | Specify the text file encoding to use. Leave blank to use the default encoding on your system. To use Unicode, specify UTF-8 or UTF-16. On first use, the PDI client searches your system for available encodings. |
| Be lenient when parsing dates? | Clear check box if you want strict parsing of data fields. If selected, dates like Jan 32nd become Feb 1st. |
| The date format Locale | This locale is used to parse dates that have been written in full such as February 2nd, 2016. Parsing this date on a system running in the French (fr_FR) locale would not work because February is called Février in that locale. |
| Add filenames to result | Adds filenames to generate a filenames list. |
Error Handling tab
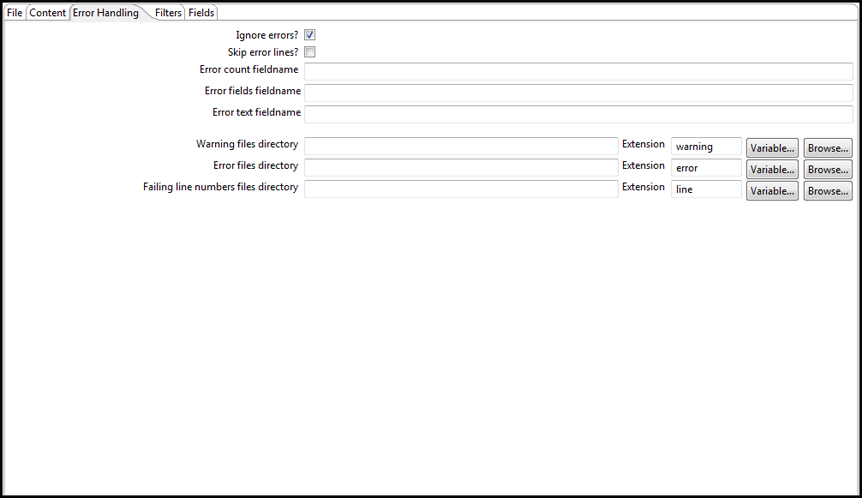
In the Error Handling tab, you can specify how the step reacts when errors occur, such as malformed records, bad enclosure strings, wrong number of fields, and premature line ends.
| Option | Description |
| Ignore errors? | Select if you want to ignore errors during parsing. |
| Skip error lines? | Select if you want to skip those lines that contain errors. You can generate an extra file that contains the line numbers where the errors occur. Lines with errors are not skipped. The fields that have parsing errors are empty (null). |
| Error count field name | Add a field to the output stream rows. This field contains the number of errors on the line. |
| Error fields field name | Add a field to the output stream rows. This field contains the field names on which an error occurred. |
| Error fields text field name | Add a field to the output stream rows. This field contains the descriptions of the parsing errors that have occurred. |
| Warnings file directory | When warnings are generated, they are placed in this directory. The name of that file is <warning dir>/filename.<date_time>.<warning extension>. |
| Error files directory | When errors occur, they are placed in this directory. The name of the file is <errorfile_dir>/filename.<date_time>.<errorfile_extension>. |
| Failing line numbers files directory | When a parsing error occurs on a line, the line number is placed in this directory. The name of that file is <errorline dir>/filename.<date_time>.<errorline extension>. |
Filters tab
In the Filters tab, you can specify the lines you want to skip in the text file.
| Option | Description |
| Filter string | The string for which to search. |
| Filter position | The position where the filter string must be placed in the line. Zero (0) is the first position in the line. If you specify a value below zero, the filter string is searched for in the entire string. |
| Stop on filter | Enter Y here if you want to stop processing the current text file when the filter string is encountered. |
| Positive match | Turns filters into positive mode when turned on. Only lines that match this filter will be passed. Negative filters take precedence and are immediately discarded. |
Fields tab
In the Fields tab, you can specify the information about the name and format of the fields being read from the text file.
| Option | Description |
| Name | Name of the field. |
| Type | Type of the field can be either String, Date, or Number. |
| Format | See Number formats for a complete description of format symbols. |
| Position | The position is needed when processing the Fixed filetype. It is zero-based, so the first character is starting with position 0. |
| Length |
The value of this field depends on format:
|
| Precision |
The value of this field depends on format:
|
| Currency | Used to interpret numbers such as $10,000.00 or E5.000,00. |
| Decimal | A decimal point can be a period (.) as in 10,000.00 or it can be a comma (,) as in 5.000,00. |
| Group | A grouping can be a comma (,) as in 10,000.00 or a period (.) as in 5.000,00. |
| Null if | Treat this value as null. |
| Default | Default value in case the field in the text file was not specified (empty). |
| Trim type |
Trim the type before processing. You can specify one of the following options:
|
| Repeat | If the corresponding value in this row is empty, repeat the one from the last time it was not empty (Y or N). |
Number formats
Use the following table to specify number formats. For further information on valid numeric formats used in this step, view the Number Formatting Table.
| Symbol | Location | Localized | Meaning |
| 0 | Number | Yes | Digit. |
| # | Number | Yes | Digit, zero shows as absent. |
| . | Number | Yes | Decimal separator or monetary decimal separator. |
| - | Number | Yes | Minus sign. |
| , | Number | Yes | Grouping separator. |
| E | Number | Yes | Separates mantissa and exponent in scientific notation. Need not be quoted in prefix or suffix. |
| ; | Subpattern boundary | Yes | Separates positive and negative patterns. |
| % | Prefix or suffix | Yes | Multiply by 100 and show as percentage. |
| ‰(/u2030) | Prefix or suffix | Yes | Multiply by 1000 and show as per mille. |
| ¤ (/u00A4) | Prefix or suffix | No | Currency sign, replaced by currency symbol. If doubled, replaced by international currency symbol. If present in a pattern, the monetary decimal separator is used instead of the decimal separator. |
| ‘ | Prefix or suffix | No | Used to quote special characters in a prefix or suffix, for example, '#'# formats 123 to #123. To create a single quote itself, use two in a row: # o''clock. |
Scientific notation
In a pattern, the exponent character immediately followed by one or more digit characters indicates scientific notation, for example, 0.###E0 formats the number 1234 as 1.234E3.
Date formats
Use the following table to specify date formats. For further information on valid date formats used in this step, view the Date Formatting Table.
| Letter | Date of Time Component | Presentation | Examples |
| G | Era designator | Text | AD |
| y | Year | Year | 1996 or 96 |
| M | Month in year | Month | July, Jul, or 07 |
| w | Week in year | Number | 27 |
| W | Week in Month | Number | 2 |
| D | Day in year | Number | 189 |
| d | Day in month | Number | 10 |
| F | Day of week in month | Number | 2 |
| E | Day in week | Text | Tuesday or Tue |
| a | am/pm marker | Text | PM |
| H | Hour in day (0-23) | Number 0 | n/a |
| k | Hour in day (1-24) | Number 24 | n/a |
| K | Hour in am/pm (0-11) | Number 0 | n/a |
| h | Hour in am/pm (1-12) | Number 12 | n/a |
| m | Minute in hour | Number 30 | n/a |
| s | Second in minute | Number 55 | n/a |
| S | Millisecond | Number 978 | n/a |
| z | Time zone | General time zone | Pacific Standard Time, PST, or GMT-08:00 |
| Z | Time zone | RFC 822 time zone | -0800 |
Metadata injection support
All fields of this step support metadata injection except for the Hadoop Cluster field. You can use this step with ETL metadata injection to pass metadata to your transformation at runtime.